TransitNXT– a major progress in translation efficiency

After more than a quarter of a century of development, here is TransitNXT, sophisticated software with translation memory and fuzzy logic. It is a well-arranged software that anyone can use easily and quickly. The software provides advanced users with extensive enhanced functions, making the implementation of translation and localization projects incomparably more efficient in TransitNXT. The target is to make the work of all the participants in a translation project simpler, quicker and better. The increasing group of Transit users confirms that we are on the right track. Join the tens of thousands of satisfied users worldwide.
Efficient translation memory
TransitNXT remembers each sentence that you translate. If an identical sentence occurs in a text for translation in the future, it is automatically pretranslated. Therefore, it is not a machine translation, but a repeated use of your previous translations. You always have the option of checking and modifying the pretranslation, if necessary.
If the sentence is not identical with the previously translated sentence, TransitNXT will offer you a “fuzzy match”. It will mark the difference between both sentences using colours. The translator will only translate the differing parts, and will use the suggestion from the translation memory for matching the rest of the sentence. This is, again, a repeated use of your own work.
Only TransitNXT offers pretranslation and fuzzy matches in conjunction with a context comparison, i. e. the comparison of neighbouring sentences. Suggestions are then incomparably more precise than in other CAT tools .
Pretranslation and fuzzy matches from the translation memory will make the translator’s work ever faster and more precise. Over twenty years of Transit’s history have shown that the translator manages to translate 30–70 per cent more text with Transit than in the conventional way, not to mention the higher standard of work thanks to the consistency of translation resulting from the use of translation memory.
“Know what you want to translate”
TransitNXT suggests fuzzy matches based on an analysis of the texts in the original. MindReader is a unique function that further extends this feature of TransitNXT: By comparing the written text with previously written sentences, it looks for similar sentences also in the target , suggesting them to the user. With just slight exaggeration we can say that TransitNXT ”reads your mind”, looking for the sentence you are most probably going to write. If a similar sentence is found in the translation memory, it will be suggested to you. The objective is to create a more efficient and a more precise translation.
How does Transit work?
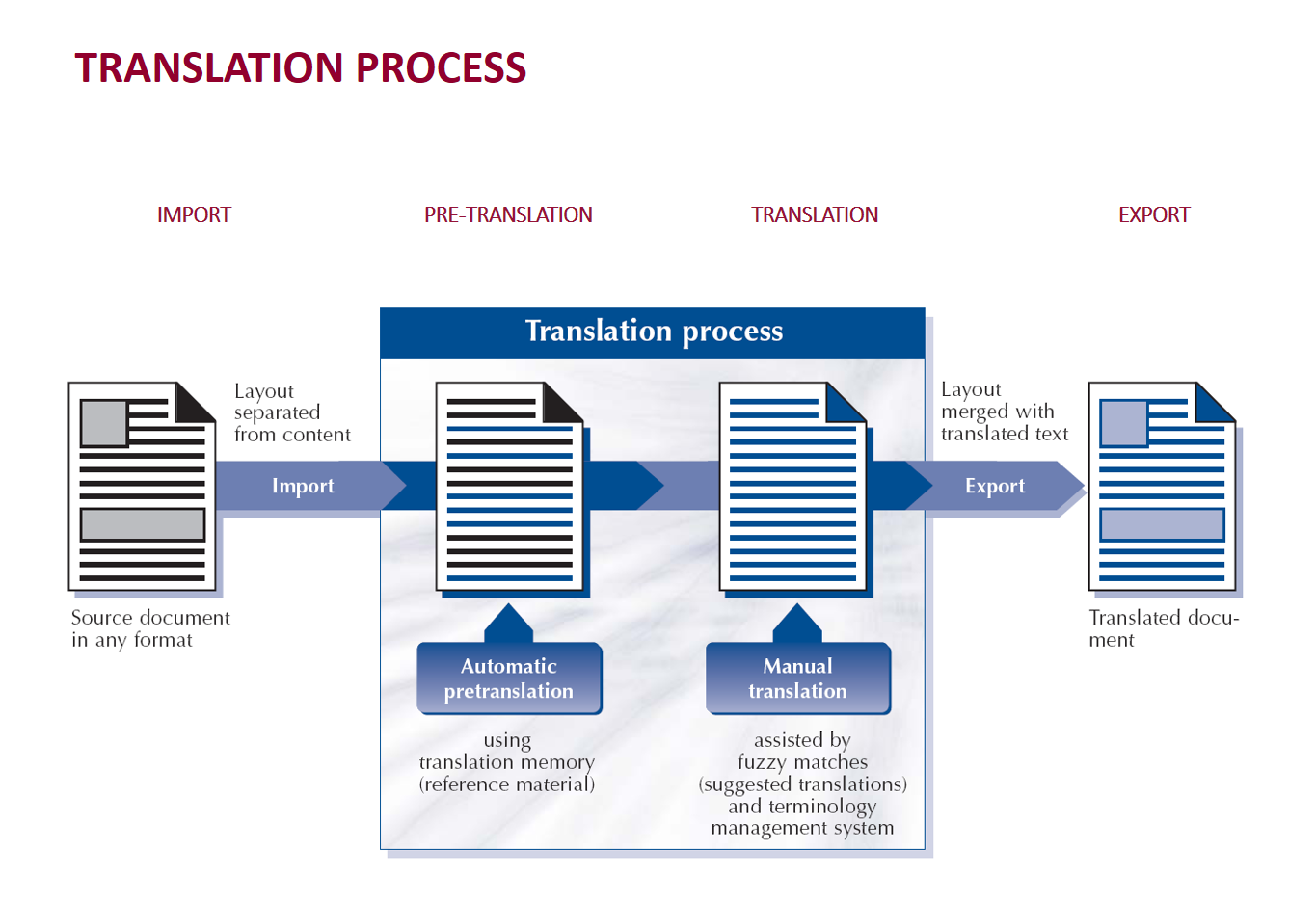
In the first step, Transit imports files from the original format, such as Word, HTML or InDesign. The formatting information is protected against modifying by the translator. The translator then works in a clean and tidy environment, focusing on translation and terminology, not on formatting and document layout. After the translation is completed, Transit links the formatting information with the text again and exports the final translation into the original format. The result is a document with the same formatting as the original one, the translator does not need to worry about the graphic design. The same applies to HTML files: their localization into a foreign language is a breeze, even for a user without any knowledge of the HTML code. You just translate the text while the code remains hidden. The output is a localized website.
“Expanding the translator’s brain”
Transit works as an extension of the translator’s brain: the search in the translation memory and project dictionaries goes on automatically in the background, allowing you to concentrate on your work. All of these options can be set to appear in floating windows. They appear only when the software finds a reasonable suggestion. Your workspace is not cluttered by windows that you don’t actually need.
Searching and finding
If you need to find anything in the current or previous translations, either in the original or the target, there is nothing easier with Transit. Just use the dual concordance search function: enter a term, and Transit will find all instances of the search term, including declined or conjugated forms, using its integrated morphological analysis function. It will display the whole sentence in both languages, including the neighboring sentences for context if needed. Lose no more time by searching manually in the files.
Quality assurance
Many checking functions may be applied to the completed translation in Transit. In the classical spelling check, the in-built database can be extended by words from your previous completed translations or dictionaries. Transit does not mark as errors the terms which it does not have in its database but which have been approved by the translator. Other checking functions:
excess/missing spaces, double spaces
numbers
complying with conventions relating to the decimal point and thousand separator for the given language
formatting (such as missing bold or italics)
using a binding project terminology
missing sentences in the translation
protected words (terms not intended for translation)
duplicate words
words written in capital characters
maximum sentence length (if defined)
Project administration and organization
You can use many criteria to organize your projects, the source and target languages, the file format, the date of creation or last modification, the client name, the project status, the user name, the location of the working file, etc. You always have a whole view of the current or previous projects. For every customer you can define billing units (a word, a line or a standard page) and prices for each language pair. A price calculation for the customer is a matter of one click, including the possibility of accounting for various prices for a new translation, fuzzy matches and internal repetitions. The price statistics can also be used as a basis for a translation order with an external supplier. An ideal function for commissioning a translation: after selecting a translator from a database, well-arranged statistics with his or her prices are created within a second. If you make the price statistics binding for every translator, you will avoid a lot of paperwork comparing supplier invoices with your data.